
















Other Method Related/Applied Documents On This Sitemethods and procedures for collecting democide data "Libertarianism and International Violence" "Libertarianism, Violence Within States, and the Polarity Principle" "The Conflict Helix and the Probability of a Korean War," "Power kills: genocide and mass murder," "Is collective violence correlated with social pluralism?" "Libertarianism and International Violence" "Libertarianism, Violence Within States, and the Polarity Principle" "Is collective violence correlated with social pluralism?" |
Note for Rummel web site visitors: Many of the statistical analyses on this web site use factor analysis to dimensionalize data or to uncover underlying causes or factors. A number of these are consolidated in the "Dimensions of Democide, Power, Violence, and Nations" part of the site. This article (a summary of Rummel's Applied Factor Analysis, 1970) may therefore be helpful to those who would like to understand better this method in association with the democide and conflict results presented here, or to apply it themselves.
The few basic variables and propositions central to understanding remain to be determined. The systematic dependencies and correlations among these variables have been charted only roughly, if at all, and many, if not most, can be measured only on presence-absence or rank order scales. And to take the data on any one variable at face value is to beg questions of validity, reliability, and comparability.
Confronted with entangled behavior, unknown interdependencies, masses of qualitative and quantitative variables, and bad data, many social scientists are turning toward factor analysis to uncover major social and international patterns.
Factor analysis is not without cost, however. It is mathematically complicated and entails diverse and numerous considerations in application. Its technical vocabulary includes strange terms such as eigenvalues, rotate, simple structure, orthogonal, loadings, and communality. Its results usually absorb a dozen or so pages in a given report, leaving little room for a methodological introduction or explanation of terms. Add to this the fact that students do not ordinarily learn factor analysis in their formal training, and the sum is the major cost of factor analysis: most laymen, social scientists, and policy-makers find the nature and significance of the results incomprehensible.
The problem of communicating factor analysis is especially crucial for peace research. Scholars in this field are drawn from many disciplines and professions, and few of them are acquainted with the method. As our empirical knowledge of conflict processes, behavior, conditions, and patterns become increasingly expressed in factor analytic terms, those who need this knowledge most in order to make informed policy decisions may be those who are most deterred by the packaging. Indeed, they are unlikely to know that this knowledge exists.
A conceptual map, therefore, is needed to guide the consumers of findings in conflict and international relations through the terminological obstacles and quantitative obstructions presented by factor studies. The aim of this paper is to help draw such a map. Specifically, the aim is to enhance the understanding and utilization of the results of factor analysis. Instead of describing how to apply factor analysis or discussing the mathematical model involved, I shall try to clarify the technical paraphernalia which may conceal important substantive data, propositions, or scientific laws.
By way of orientation, the first section of this paper will present a brief conceptual review of factor analysis. In the second section the scientific context of the method will be discussed. The major uses of factor analysis will be listed and its relation to induction and deduction, description and inference, causation and explanation, and classification and theory will be considered. To aid understanding, the third section will outline the geometrical and algebraic factor models, and the fourth section will define the factor matrices and their elements--the vehicles for presenting factor results. Since comprehending factor rotation is important for interpreting the findings, the fifth and final section is devoted to clarifying its significance.
A bibliography of factor analysis texts and applications to conflict and international relations is given in an appendix.
What factor analysis does is this: it takes thousands and potentially millions of measurements and qualitative observations and resolves them into distinct patterns of occurrence. It makes explicit and more precise the building of fact-linkages going on continuously in the human mind.
Let us look at a concrete example. Table 1 presents information on fourteen nations for ten characteristics. The nations are selected to reflect major regional, political, economic, and cultural groupings; the characteristics reflect different facets of each nation, including domestic instability and foreign conflict. The table thus contains 14 X 10, or 140 pieces of information for 1955. Factor analysis addresses itself to this question: "What are the patterns of relationship among these data?"
These patterns can be viewed from two perspectives. One can look at the pattern of variation of nations across their characteristics, and then group the nations by their profile similarity. One might group together nations which are all high on GNP per capita, low on trade, high on power, etc. When applied to discern patterns of profile similarity of individuals, groups, or nations, the analysis is called Q-factor analysis.
The regularity in the data of Table 1 can be looked at from a second perspective, however. The focus now is the patterns of variation of characteristics. In Table 1, for example, nations high on GNP per capita also appear low on trade and power. There is a regularity, therefore, in the nation values on these three characteristics, and this regularity is described as a pattern of variation. Many of our social concepts define such patterns. For example, the concept of 11 economic development" involves (among other things) GNP per capita, literacy, urbanization, education, and communication; it is a pattern because these characteristics are highly intercorrelated with each other. Factor analysis applied to delineate patterns of variation in characteristics is called R-factor analysis.
What actual patterns of characteristics are revealed for the data in Table 1 by factor analysis? Figure 1 displays the four major kinds of regularity in the interrelationships between the characteristics: power, US voting agreement, foreign conflict, and international law. They involve, respectively, 27.6, 21.0, 16.2, and 15.3 percent of the variation
Each pattern in Figure 1 is laid out in three isobars. The central isobar includes characteristics with at least 75 percent of their variation involved in the pattern. These are most central to interpreting the pattern. The two remaining isobars define characteristics related to the pattern in the range of 50-74 percent and 25-49 percent of their variation, respectively. These groups of isobars show
To display another perspective, Figure 2 plots these four patterns as profiles for the nations in Table 1. On the horizontal axis, nations are ordered from low to high power pattern values. Magnitudes on the vertical axis are in standard scores, which is to say that the average score is zero and 95.5 percent of the fourteen nations will (if normally distributed) fall between scores of +2.00 and -2.00; 68.3 percent of them will fall between scores of +1.00 and -1.00. Each pattern has a different shape, which illustrates what is meant by saying that factor analysis divides the regularity in the data into its distinct patterns. If each of the ten characteristics in Table 1 were plotted as was done for the patterns in Figure 2, and those characteristics with similarly-shaped plots were grouped together, there would be four major groups, and the modal plot within each group would correspond to each of the patterns shown. Figure 1 and Figure 2 are alternative representations of the results of factoring Table 1.
Interdependency and pattern delineation. If a scientist has a table of data--say, UN votes, personality characteristics, or answers to a questionnaire--and if he suspects that these data are interrelated in a complex fashion, then factor analysis may be used to untangle the linear relationships into their separate patterns. Each pattern will appear as a factor delineating a distinct cluster of interrelated data.
Parsimony or data reduction. Factor analysis can be useful for reducing a mass of information to an economical description. For example, data on fifty characteristics for 300 nations are unwieldy to handle, descriptively or analytically. The management, analysis, and understanding of such data are facilitated by reducing them to their common factor patterns. These factors concentrate and index the dispersed information in the original data and can therefore replace the fifty characteristics without much loss of information. Nations can be more easily discussed and compared on economic development, size, and politics dimensions, for example, than on the hundreds of characteristics each dimension involves.
Structure. Factor analysis may be employed to discover the basic structure of a domain. As a case in point, a scientist may want to uncover the primary independent lines or dimensions--such as size, leadership, and age--of variation in group characteristics and behavior. Data collected on a large sample of groups and factor analyzed can help disclose this structure.
Classification or description. Factor analysis is a tool for developing an empirical typology.
Scaling. A scientist often wishes to develop a scale on which individuals, groups, or nations can be rated and compared. The scale may refer to such phenomena as political participation, voting behavior, or conflict. A problem in developing a scale is to weight the characteristics being combined. Factor analysis offers a solution by dividing the characteristics into independent sources of variation (factors). Each factor then represents a scale based on the empirical relationships among the characteristics. As additional findings, the factor analysis will give the weights to employ for each characteristic when combining them into the scales. The factor score results (see Section 4.5 below) are actually such scales, developed by summing characteristics times these weights.
Hypothesis testing. Hypotheses abound regarding dimensions of attitude, personality, group, social behavior, voting, and conflict. Since the meaning usually associated with "dimension" is that of a cluster or group of highly intercorrelated characteristics or behavior, factor analysis may be used to test for their empirical existence. Which characteristics or behavior should, by theory, be related to which dimensions can be postulated in advance and statistical tests of significance can be applied to the factor analysis results.
Besides those relating to dimensions, there are other kinds of hypotheses that may be tested. To illustrate: if the concern is with a relationship between economic development and instability, holding other things constant, a factor analysis can be done of economic and instability variables along with other variables that may affect (hide, mediate, depress) their relationship. The resulting factors can be so defined (rotated) that the first several factors involve the mediating measures (to the maximum allowed by the empirical relationships). A remaining independent factor can be calculated to best define the postulated relationships between the economic and instability measures. The magnitude of involvement of both variables in this pattern enables the scientist to see whether an economic development-instability pattern actually exists when other things are held constant.
Data transformation. Factor analysis can be used to transform data to meet the assumptions of other techniques. For instance, application of the multiple regression technique assumes (if tests of significance are to be applied to the regression coefficients) that predictors--the so-called independent variables--are statistically unrelated (Ezekiel and Fox, 1959, pp. 283-84). If the predictor variables are correlated in violation of the assumption, factor analysis can be employed to reduce them to a smaller set of uncorrelated factor scores. The scores may be used in the regression analysis in place of the original variables, with the knowledge that the meaningful variation in the original data has not been lost.
Exploration. In a new domain of scientific interest like peace research, the complex interrelations of phenomena have undergone little systematic investigation. The unknown domain may be explored through factor analysis. It can reduce complex interrelationships to a relatively simple linear expression and it can uncover unsuspected, perhaps startling, relationships. Usually the social scientist is unable to manipulate variables in a laboratory but must deal with the manifold complexity of behaviors in their social setting. Factor analysis thus fulfills some functions of the laboratory and enables the scientist to untangle interrelationships, to separate different sources of variation, and to partial out or control for undesirable influences on the variables of concern.
Mapping. Besides facilitating exploration, factor analysis also enables a scientist to map the social terrain. By mapping I mean the systematic attempt to chart major empirical concepts and sources of variation. These concepts may then be used to describe a domain or to serve as inputs to further research. Some social domains, such as international relations, family life, and public administration, have yet to be charted. In some other areas, however, such as personality, abilities, attitudes, and cognitive meaning, considerable mapping has been done.
Theory. As will be discussed in Section 2.5 below, the analytic framework of social theories or models can be built from the geometric or algebraic structure of factor analysis.
Factor analysis is most familiar to researchers as an exploratory tool for unearthing the basic empirical concepts in a field of investigation. Representing patterns of relationship between phenomena, these basic concepts may corroborate the reality of prevailing concepts or may be so new and strange as to defy immediate labeling. Factor analysis is often used to discover such concepts reflecting unsuspected influences at work in a domain. The delineation of these interrelated phenomena enables generalizations to be made and hypotheses posed about the underlying influences bringing about the relationships. For example, if a political scientist were to factor the attributes and votes of legislators and were to find a pattern involving urban constituencies and liberal votes, he could use this finding to develop a theory linking urbanism and liberalism. The ability to relate data in a meaningful fashion is a prime aspect of induction and, for this, factor analysis is useful and efficient.
Factor analysis may also be employed deductively, in two ways. One way is to elaborate the geometric or algebraic structure of factor analysis as part of a theory. Within the theory the factor analysis model can then be used to arrive at deductions about phenomena. This approach is described more fully in Section 2.5 below.
The second deductive approach is to hypothesize the existence of particular dimensions and then to factor analyze the data to see whether these dimensions emerge.
Description may be only an intermediate goal, however. The ultimate goal may be to connect a number of descriptive studies to make generalizations about what patterns exist for such phenomena as, say, legislative voting, foreign conflict, political systems, personality, or role behavior.
Description, then, and generalization from a number of descriptive studies have been the tradition in applied factor analysis. Although tests of significance can be determined for the factors and loadings of a particular sample, factor analysis itself does not require such tests.
Modem science conceives of causation as a temporal regularity of phenomena or, more precisely, a functional (mathematical) relationship between phenomena. The term "cause" is then simply an expression of uniform relationships, that is, of a generally observed concurrence or concomitance of phenomena. Even though this interpretation drops out interesting connotations like "to bring about," or "to influence," it removes a fuzziness from the concept and gives it a denotation consonant with scientific method and philosophy.
Does factor analysis define factors, then, that can be called causes of the patterns they represent? The answer must be yes.
The term explanation adds nothing to the term cause. Although laden in the social sciences with a surplus meaning associated with verstehen, a feeling of understanding or getting the sense of something,
Prediction itself is based on the identification of causal relations, i.e., regularity. Therefore, if a factor can be called a cause, it can be called an explanation.
If one wants to avoid controversy over causation, on the other band, factor patterns may be treated as purely descriptive or classificatory. A factor name like "turmoil" will then be a noun describing phenomena sharing one characteristic: appearance in time or space with a certain uniformity. "House," "horse," "social group," "legislature," and "nation" are such nouns, and factors may be conceived likewise. "Economic development" or "size," as factors actually delineated through factor analysis (Rummel, 1972), can be descriptive categories subsuming a pattern of telephones per capita, GNP per capita, and vehicles per capita as distinct from a pattern of population, area, and national income.
A scientific theory consists of two components:
The empirical component of theories is operational. It fastens the abstract analytic part of a theory to the facts. While the analytic part need have no empirical interpretation, the empirical component must verifiably link to data for a theory to apply to "reality."
A confusion between the empirical and analytic parts of a theory may have militated against a more theoretical use of factor analysis. The geometric or algebraic nature of the factor model can structure the analytic framework of theory. The factors themselves can be postulated. From them, operational deductions with empirical content can be derived and tested.
The factor model represents a mathematical formalism departing from the calculus functions of classical physics. The analytic part of the factor model is akin to that of quantum theory.
Since factor analysis incorporates analytic possibilities as a theory and empirical techniques for connecting the theory to social phenomena, its potentiality promises much theoretical development for the social sciences. Looking ahead for a century, I suggest that factor analysis and the complementary multiple regression model are initiating a scientific revolution in the social sciences as profound and far-reaching as that initiated by the development of the calculus in physics.
Other factor models are image analysis, canonical analysis, and alpha analysis. Image analysis has the same purpose as common factor analysis, but more elegant mathematical properties. Canonical analysis defines common factors for a sample of cases that are the best estimates of those for the population; it enables tests of significance. Alpha analysis defines common factors for a sample of variables that are the best estimates of those in a universe of content.
It would be beyond the purpose of this paper to discuss these models in any detail. (For such a discussion, see Rummel, 1970, Chapter 5.) In the following sections only their general mathematical properties will be outlined. These properties clearly distinguish the factor analysis models from others used in the social sciences, such as analysis of variance and multiple regression, and justify our consideration of these properties in reference to a generalized factor model.
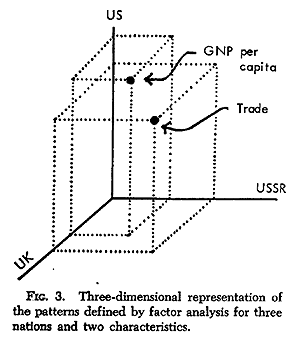 An understanding of the patterns defined by factor analysis can be enhanced through a geometric interpretation. Each nation of Table 1 can be thought of as defining a coordinate axis of a geometric space. For example, the US, the UK, and the USSR can define a three-dimensional space as given in Figure 3. Imagine that the axis for the UK is projecting at right angles from the paper. Although pictorially constrained to three dimensions, the space can be analytically extended to fourteen dimensions at right angles to each other and thus represent the fourteen nations in Table 1.
An understanding of the patterns defined by factor analysis can be enhanced through a geometric interpretation. Each nation of Table 1 can be thought of as defining a coordinate axis of a geometric space. For example, the US, the UK, and the USSR can define a three-dimensional space as given in Figure 3. Imagine that the axis for the UK is projecting at right angles from the paper. Although pictorially constrained to three dimensions, the space can be analytically extended to fourteen dimensions at right angles to each other and thus represent the fourteen nations in Table 1.
Now, in this space each characteristic can be considered a point located according to its value for each nation. Such a plot is shown in Figure 3 for the GNP per capita and trade values of the US, UK, and USSR. To make the plot explicit, projections for each point are drawn as dotted lines to each axis.
If for each point in Figure 3 we draw a line from the origin to the point and top the line off with an arrowhead as shown in Figure 4, then we have a vector representation of the data. The ten characteristics of Table 1 similarly plotted as vectors in an imaginary space of the fourteen nations (dimensions) would describe a vector space. In this space, consider two vectors representing any two of these characteristics for the fourteen nations.
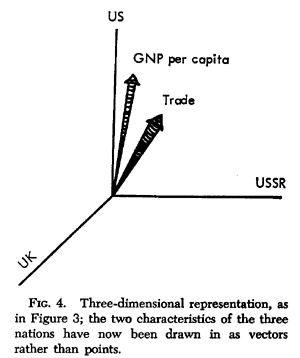 The angle between these vectors measures the relationship between the two characteristics for the fourteen nations. The closer to 90o the angle is, the less the relationship is. If two vectors are at a right angle, the characteristics they represent are uncorrelated: they have no relationship to each other. In other words, some nations will be high on one characteristic, say GNP per capita, and low on the other, say trade; some nations will be low on GNP per capita and high on trade; some nations will be high on both, and some will be low on both. No regularity exists in their covariation.
The angle between these vectors measures the relationship between the two characteristics for the fourteen nations. The closer to 90o the angle is, the less the relationship is. If two vectors are at a right angle, the characteristics they represent are uncorrelated: they have no relationship to each other. In other words, some nations will be high on one characteristic, say GNP per capita, and low on the other, say trade; some nations will be low on GNP per capita and high on trade; some nations will be high on both, and some will be low on both. No regularity exists in their covariation.
The closer the angle between the vectors is to zero, the stronger the relationship between the characteristics. An angle of zero means that nations high or low on one characteristic are proportionately high or low on the other. Obtuse angles mean a negative relationship. At the extreme, an angle of 180o between two vectors means that the two characteristics are inversely related: a nation high on one characteristic is proportionately low on the other.
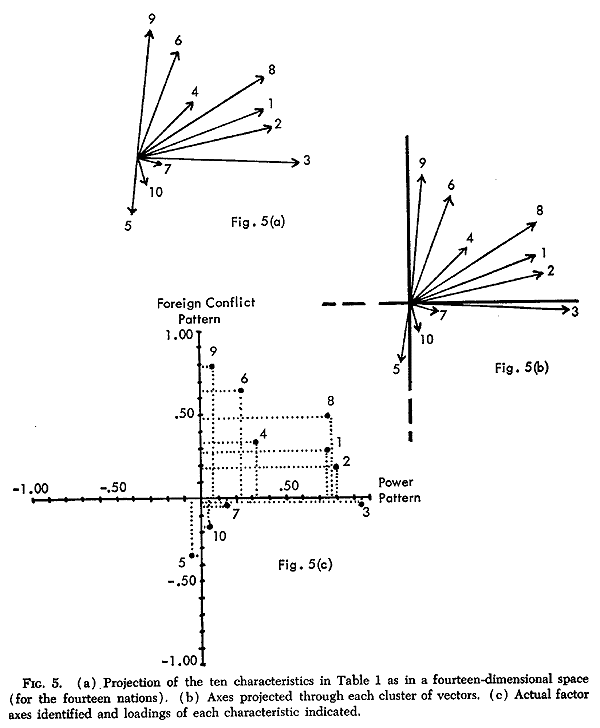
Let the ten characteristics of Table 1 be projected in the fourteen-dimensional space defined by the fourteen nations as suggested in Figure 5(a). The configuration of vectors will then reflect the data interrelationships. Characteristics that are highly interrelated will cluster together; characteristics that are unrelated will be at right angles to each other. By inspecting the configuration we can discern the distinct clusters of vectors (if such clusters exist), and these clusters index the patterns of relationship in the data: each cluster is a pattern.
Were we dealing with characteristics of two or three nations, patterns could be found by simply plotting the characteristics as vectors. What factor analysis does geometrically is this: it enables the clusters of vectors to be defined when the number of cases (dimensions) exceeds our graphical limit of three. Each factor delineated by factor analysis defines a distinct cluster of vectors.
Consider Figure 5(a) again. Factor analysis would mathematically lay out such a plot and then project an axis through each cluster as shown in Figure 5(b). This is analogous to giving each vector point in a cluster a mass of one and letting the factor axes fall through their center of gravity.
Figure 5(c) pictures the power and foreign conflict patterns of Table 1. For simplicity, the configuration of points is shown, rather than vectors, and the two factor axes are indicated (as actually derived from a factor analysis). The loadings of each characteristic (i.e., each point in space) on each axis are also displayed. This figure may clarify how factor loadings as a set of numbers can define
We will consider this geometrical perspective again when the factor matrices are described.
A traditional approach to expressing relationships is to establish the mathematical function f(X, W, Z) connecting one variable, Y, with the set of variables X, W, and Z. Such a function might be Y = 2X + 3Z - 2W, or Y = 4XW/Z. The variables on both the right and the left side of the equation are known, data are available, and it is only a question of determining the best function for describing the relationships.
Let us say, however, that we have a number of variables, Y1, Y2, Y3, and so on, but that we know neither the variables to enter in on the right side of the equation nor the functions involved. This might be the situation with UN voting, for example. We may know the votes of nations on one roll-call (Y1), a second roll-call (Y2), etc., but not know what nation characteristics are related to what roll-calls in what way. Moreover, we may not be able to measure well the characteristics, like nationalism, ideology, and democracy, that we feel might be most related to UN voting. In other words, we have data that we wish to explain mathematically but the variables that would give us this explanation are unknown or unmeasureable. We are then in the same dilemma the nuclear physicist was in decades ago in describing quantum phenomena; and like him, we resort to an untraditional mathematical approach.
Let us assume that our Y variables are related to a number of functions operating linearly. That is,
Equation 1:
- Y1 =
11F1 +
- Y2 =
- Y3 =
- . . .
- . . .
- . . .
- Yn =
- where:
- Y = a variable with known data
- F = a function, f ( ) of some unknown variables.
It is crucial in understanding factor analysis to remember that F stands for a function of variables and not a variable. For example, the functions might be F 1 = XW + 2Z, and F2 = 3X2Z/W1/2. The unknown variables entering into each function, F, of Equation 1 are related in unknown ways, although the equations relating the functions themselves are linear.
Within this algebraic perspective, what does factor analysis do? By application to the known data on the Y variables, factor analysis defines the unknown F functions. The loadings emerging from a factor analysis are the a constants. The factors are the F functions. The size of each loading for each factor measures how much that specific function is related to Y. For any of the Y variables of Equation 1 we may write
Equation 2:
- Y =
- with the F's representing factors and the
We may find that some of the F functions are common to several variables. These are called group factors and their delineation is often the goal of factor analysis. For UN voting with each Y variable being a UN roll-call, for example, Alker and Russett (1965) found "supernationalism" and "cold war" as group factors, among others, related to voting.
Besides determining the loadings, , factor analysis will also generate data (scores) for each case (individual, group, or nation) on each of the F functions uncovered. These derived values for each case are called factor scores. They, along with the data on Y and Equation 1, give a mathematical relationship among data as useful and important as the classical equations like Y = 2X + 3Z
Let us look at the data of Table 1 in the context of this Section. The table lists data on ten variables representing characteristics of fourteen nations. A factor analysis of these data brought out four functions, F, as linearly related to two or more variables. These results enable us to give content to Equation 1. Leaving out those functions, F, that are multiplied by small or near-zero loadings, , the findings are:

When the results are arranged in this fashion the patterns of relationship are well brought out; a pattern is now defined as a number of variables similarly related to the same F function.
The full correlation matrix involved in the factor analysis is usually shown if the number of variables analyzed is not overly large. Often, however, the matrix is presented without comment. The factor analysis and not the correlation matrix is the aim, and it is on the factors that the discussion will focus. Nevertheless, the correlation matrix contains much useful knowledge and the reader can peruse it for relationships between pairs of variables (see Understanding Correlation for the meaning and nature of correlation coefficients). Specifically, the correlation matrix has the following features.
One estimate commonly employed for the communality measure is the squared multiple correlation coefficient (SMC) of one variable with all the others. The SMC multiplied by 100 measures the percent of variation that can be produced (predicted, accounted for, generated, or explained) for one variable from all the others. To refer to our example again: Table 2 has SMC values in the principal diagonal. For foreign conflict this is .61. This means that 61 percent of the foreign conflict data in Table 2 can be predicted from (is dependent upon) data on the remaining nine characteristics. By knowing a nation's data on the nine characteristics we could determine the incidence of foreign conflict behavior for that nation within 61 percent of the true value, on the average.
With an understanding of the key interpretations just given, the reader should be able to consult a correlation matrix and test a number of hypotheses and theories. Many of our social hypotheses involve relations between two variables, and it is in the correlation matrix that such empirical relations are described.
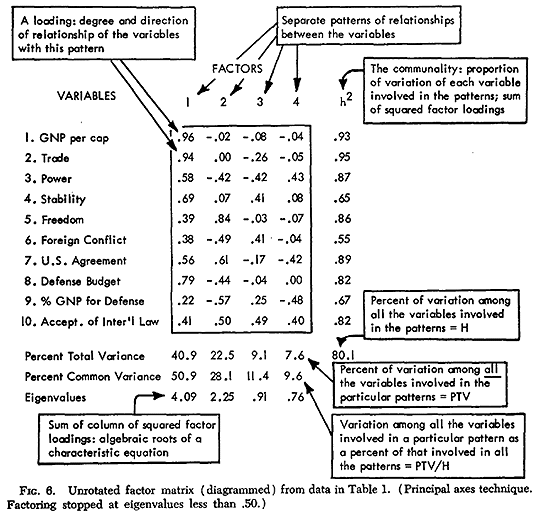
Figure 6 displays the format of an unrotated factor matrix. The columns define the factors; the rows refer to variables. In the intersection of row and column is given the loading for the row variable on the column factor. The h2 column on the right of the table, and the rows beneath the table for total and common variance and eigenvalues, give additional information to be described below. The features of the matrix which are useful for interpretation are as follows:
, measure which variables are involved in which factor pattern and to what degree (see Equation 1 and Equation 2).One can look at this percent figure as the percent of data on a variable that can be produced or predicted by knowing the values of a case (such as a nation) on the pattern or on the other variables involved in the same pattern. Another perspective is that the percent figure is the reliability of prediction of a variable from the pattern or from the other variables in the same pattern. By comparing the factor loadings for all factors and variables, those particular variables involved in an independent pattern can be defined, and those variables most highly related to a pattern can also be seen.
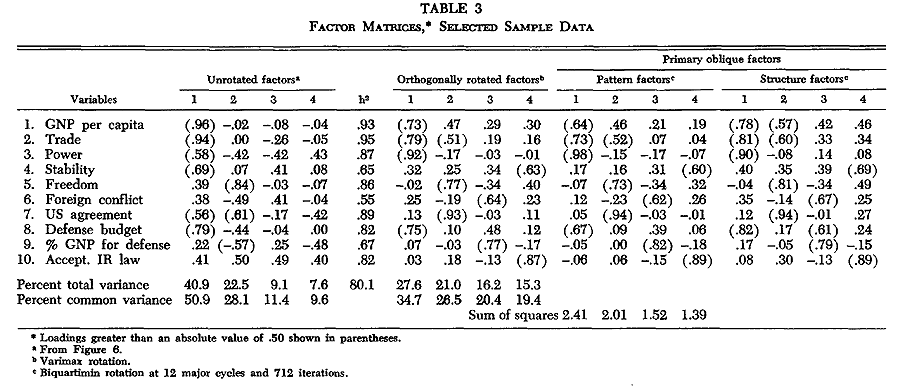
For example, consider the unrotated factor loadings for the ten characteristics as shown in the first section of Table 3. Let a pattern be limited to those variables with 25 percent or more of their variation involved in a pattern (loading of .50, squared and multiplied by 100). Then the first pattern of interrelationships
This communality may also be looked at as a measure of uniqueness. By subtracting the percent of variation in common with the patterns from 100, the uniqueness of a variable is determined. This indicates to what degree a variable is unrelated to the others--to what degree the data on a variable cannot be derived from (predicted from) the data on the other variables. In Table 3, for example, foreign conflict has a communality of .55. This says that 55 percent of the foreign conflict behavior as measured for the fourteen nations can be predicted from a knowledge of nation values on the four patterns; and that 45 percent of it is unrelated to the other nine characteristics.
The h2 value for a variable is calculated by summing the squares of the variable's loadings. Thus for power in Table 3 we have (.58)2 + (-.42)2 + (-.42)2 + (.43)2 = .87, the h2 value.
The sum of these figures for each pattern equals the sum of the column of h2 multiplied by 100. Looking along the row of percent of total variance figures and up the column of h2, one can see how the order in the data is divided by pattern and by variable.
The percent of total variance figure for a factor is determined by summing the column of squared loadings for a factor, dividing by the number of variables, and multiplying by 100.
Not all factor studies present the h2 values or the percent of common or total variance. From the points just made, however, the reader should be able to calculate them himself. In conjunction, information on the factor loadings and on communalities should enable the reader to relate the findings in an unrotated matrix to his particular concerns.
The unrotated factors successively define the most general patterns of relationship in the data. Not so with the rotated factors. They delineate the distinct clusters of relationships, if such exist. This is mentioned here to alert the reader to this difference. The distinction is clarified with illustrations in Section 5.
The following features characterize the rotated matrix:
Oblique rotation means that the best definition of the uncorrelated and correlated cluster patterns of interrelated variables is sought. Orthogonal rotation defines only uncorrelated patterns; oblique rotation has greater flexibility in searching out patterns regardless of their correlation. This difference is elaborated with geometric illustrations in Section 5.
Oblique rotation takes place in one of two coordinate systems: either a system of primary axes or a system of reference axes. The reference axes give a slightly better definition of the clusters of interrelated variables than do the primary ones. For each set of axes there are two possible matrices: factor structure and factor pattern matrices. It is irrelevant to the consumer of factor results whether oblique primary or reference factors are given. There is an important difference, however, between the pattern matrix and the structure matrix.
The third section of Table 3 displays the (primary) oblique pattern factor matrix for the ten national characteristics. These may be compared with the orthogonally rotated factors shown in the second section. Note how much more distinct the patterns are when defined by oblique rotation (the pattern matrix) than by orthogonal rotation. There are fewer moderate loadings and more high and low loadings, thus giving a better definition of the pattern of relationships.
By this time, the many distinctions mentioned may have created more confusion than understanding. Table 4 shows the important differences for the several matrices considered. The difference between primary and reference matrices is one of geometric perspective. Reference matrices give a slightly better definition of the oblique patterns and are preferred by psychologists. Because of a simpler geometrical representation, however, I often use the primary matrices.
What does a nonzero correlation between two factors mean? It means that the data patterns themselves have a relationship, to the degree measured by the factor correlations. The idea that patterns can be related is not strange, since we continually deal with such notions in social theorizing. Weather patterns are related to transportation patterns, for example, and a modernization pattern is related to cultural patterns. Factor analysis makes these links explicit through oblique rotation and the factor correlation matrix.
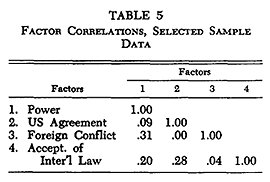
Table 5 presents the factor correlations for the oblique factors shown in Table 1. From Table 5 it can be seen that voting agreement with the US and foreign conflict patterns are in fact orthogonal (uncorrelated) to each other. The foreign conflict pattern does have some positive relationship (.31) to the power pattern, however.
Sometimes the factor correlation matrix can itself be factor analyzed, as was the variable correlation matrix. This will uncover the pattern of relationships among the factors; the interpretation of these patterns does not differ from those found for the variable correlations. The reduction of factor interrelationships to their patterns is called higher order factor analysis.
, by which the existence of a pattern for the variables can be ascertained. The factor score matrix gives a score for each case (such as a nation) on these patterns.
The factor scores are derived in the following way: Each variable is weighted proportionally to its involvement in a pattern; the more involved a variable, the higher the weight. Variables not at all related to a given pattern--like the case of defense budget as percent of GNP, a variable unrelated to the orthogonally rotated first pattern in Table 3--would be weighted near zero. To determine the score for a case on a pattern, then, the case's data on each variable is multiplied by the pattern weight for that variable. The sum of these weight-times-data products for all the variables yields the factor score. Cases will have high or low factor scores as their values are high or low on the variables entering a pattern.
How are factor scores to be interpreted? Simply as data on any variable are interpreted. GNP as a variable, for example' is a composite of such variables as hog production, steel production, and vehicle production. Similarly, population is a composite of population subgroups. In the same fashion, factor scores on, say, an economic development pattern are a composite. The composite variables represented by factor scores can be used in other analyses or as a means of comparing cases on the patterns. But the factor scores have one feature that may not be shared by many other variables. They embody phenomena with a functional unity: the phenomena are highly interrelated in time or space.
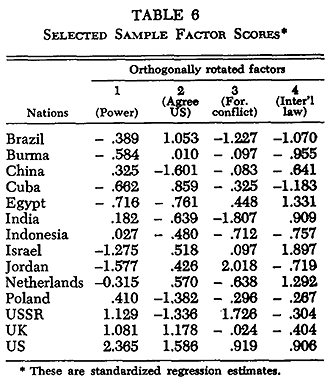
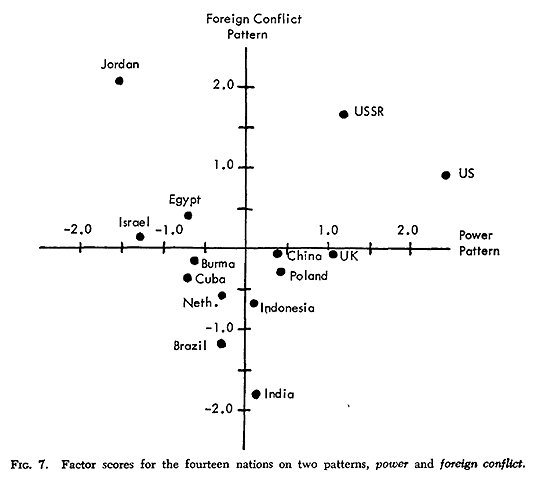
Table 6 displays the factor scores for the fourteen nations on the (orthogonally rotated) four patterns of Table 3. These scores are standardized, which means they have been scaled so that they have a mean of zero and about two-thirds of the values lie between +1.00 and -1.00. Those scores greater than +1.00 or less than -1.00, therefore, are unusually high or low. Figure 2 plots these factor scores for the four patterns separately, and Figure 7 plots scores on the power and foreign conflict patterns against each other.
Symbolic labels are simply any symbols without substantive meaning of their own. Their purpose is merely to denote the patterns. Three factor patterns, for example, may be labeled DI, D2, and D3, or A, B, and C. A label such as D, can be made equivalent to a given pattern without fear of adding surplus meaning. Alternatively, to name a pattern "economic development" or "totalitarianism" might have different connotations for different people.
Although symbolic tags are precise and help avoid confusion, they also create problems in communicating research findings and comparing studies. At the present stage of research in the social sciences, symbolic tags have yet to acquire agreed-on meanings reflecting a well-tested set of patterns, as has happened with vitamins (e.g., vitamin C).
By contrast, descriptive labels like "agreement with the US," once defined, can be easily remembered and referred to without redefinition. They are clues to factor content perhaps similar to those found by other studies. A descriptive interpretation of a pattern comprises selecting a concept that will reflect the nature of the phenomena involved. If, for example, a factor analysis of nations uncovers a pattern of intercorrelated data on total area, total population, total GNP, and magnitude of resources, the pattern might be named "size." The descriptive label is meant to categorize the findings.
In causal naming of patterns, the scientist reasons from the discovered patterns to the underlying influences causing them. The causal tag is a capsule explanation of why a pattern involves particular variables. For example, a factor pattern comprising coups and purges may be symbolically labeled "C," descriptively named "revolution," or causally termed "modernization." In the last case, the scientist may believe that the occurrence and intercorrelation among these revolutionary actions results from the social disruption of a rapid shift from a traditional society to a modem industrial nation. As another example, a factor analysis of Congressional roll call votes. may uncover a highly intercorrelated pattern of foreign policy issues. A descriptive label could be "foreign policy" pattern. Causally, however, it might be called an "isolationist" pattern by reasoning that a common isolationist attitude underlies the uniformity in foreign policy voting.
The approach to the interpretation of factor patterns is a matter of personal taste, communication, and long-run research strategy. The scientist may wish to use concepts that are congenial to the interests of the reader to facilitate communication, encourage thought about the findings, and make their use easier. There is always the danger, however, of the fallacy of misplaced concreteness. The interpretations of the findings within the research and lay community may be as much a result of the tag itself as of what the tag denotes.
This situation may be illustrated in a two-factor, eight-variable case by Figure 8. Part (a) of this figure shows the eight hypothetical variables plotted according to their data for, say, 50 cases. These fifty cases are the coordinate axes of the space.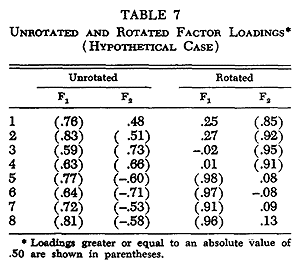 Figure 8(c) shows the variable loadings on the second factor, which is placed at right angles (orthogonal) to the first; Table 7 also gives these loadings on unrotated F2.
Figure 8(c) shows the variable loadings on the second factor, which is placed at right angles (orthogonal) to the first; Table 7 also gives these loadings on unrotated F2.
The first unrotated factor delimits the most comprehensive classification, the widest net of linkages, or the greatest order in the data. For comparative political data, a first factor could be a "political institutions" pattern, and a second might define the democratic and totalitarian poles. For international relations, the first factor could be participation in international relations, and a second factor might reflect a polarization between cooperation and conflict. For variables measuring heat, the first factor could be temperature and a second might delineate the extremes of hot and cold. For physiological measurements on adults, the first factor could be size and a second might mirror a polarization between height and girth.
Alternatively, a scientist may rotate the factors to control for certain influences on the results. He may rotate the first factor to a variable or group of variables and then rotate the subsequent factors to be at right angles (uncorrelated) with the first. This removes the effects of variables highly loaded on the first factor and enables us to assess the patterns independent of them.
Most often, however, a scientist rotates his factors to a simple structure solution. When a factor matrix is entitled "rotated factors," this almost always means a simple structure rotation. That is, each factor has been rotated until it defines a distinct cluster of interrelated variables. Through this rotation the factor interpretation shifts from unrotated factors delineating the most comprehensive data patterns to factors delineating the distinct groups of interrelated data.
Consider again the unrotated factors shown in Figure 8(c). A simple structure rotation would be equivalent to that shown in Figure 9. The new factor positions F*1 and F*2 now clearly distinguish the two clusters. This rotated factor matrix is shown in Table 7 alongside the unrotated factors.
A simple structure rotation has several characteristics of interest here:
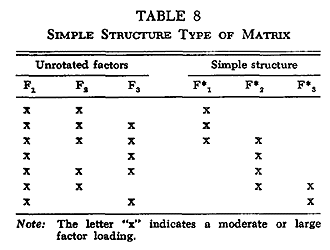
One of the chief justifications for simple structure rotation is that it determines invariant factors. This enables a comparison of the factor results of different studies. Very seldom do different scientists study exactly the same variables. But when variables overlap between studies and each study employs simple structure rotation, tests can be made to see if the same patterns are consistently emerging.
Orthogonality is a restriction placed on the simple-structure search for the clusters of interdependent variables. The total set of factors is rotated as a rigid frame, with each factor immovably fixed to the origin at a right angle (orthogonal) to every other factor. This system of factors is rotated around the origin until the system is maximally aligned with the separate clusters of variables. If all the clusters are uncorrelated with each other, each orthogonal factor will be aligned with a distinct cluster. The more correlated the separate clusters are, however, the less clearly can orthogonal rotation discriminate them. Simple structure can then only be approximated, not achieved.
Whether or not uncorrelated clusters of relationship exist in the data, orthogonal rotation will still define uncorrelated patterns of relationships. These patterns may not completely overlap with the distinct clusters, but the delineation of these uncorrelated factors is useful. Results involving uncorrelated patterns are easier to communicate, and the loadings can be interpreted as correlations. Moreover, orthogonal factors are more amenable to subsequent mathematical manipulation and analysis.
Orthogonal rotation is a subset of oblique rotations. If the clusters of relationships are in fact uncorrelated, then oblique rotation will result in orthogonal factors. Therefore, the difference between orthogonal and oblique rotation is not in discriminating uncorrelated or correlated factors but in determining whether this distinction is empirical or imposed on the data by the model.
Controversy exists as to whether orthogonal or oblique rotation is the better scientific approach. Proponents of oblique rotation usually advocate it on two grounds:
Besides yielding more information, oblique rotation is justified on epistemological grounds. One justification is that the real world should not be treated as though phenomena coagulate in unrelated clusters. As phenomena can be interrelated in clusters, so the clusters themselves can be related. Oblique rotation allows this reality to be reflected in the loadings of the factors and their correlations. A second justification is that correlations between the factors now allow the scientific search for uniformity to be carried to the second order (see Section 4.4). The factor correlations themselves may be factor analyzed to determine the more general, the more abstract, the more comprehensive relationships and the more pervasive influences underlying phenomena.
* Scanned from "Understanding Factor Analysis," The Journal of Conflict Resolution (December 1967): 444-480. Typographical errors have been corrected, clarifications added, and style updated. This was an invited paper prepared in connection with research supported by the National Science Foundation, GS-1230. For many helpful comments made on a draft of that published, I wish to thank Henry Kariel, Michael Haas, Robert Hefner, Woody Pitts, and J. David Singer. This article is a summary of Rummel (1970).1. Note omitted.
2. For a bibliography of applications of factor analysis in the social sciences (excluding psychology), see Rummel (1970). A bibliography of applications to conflict and international relations is given in the appendix below.
3. How many readers know that over a decade ago Raymond Cattell (1949) gave us the first comprehensive findings on the extent to which foreign and domestic conflict behaviors have been correlated with many socioeconomic and political characteristics of nations?
4. For a Q-factor analysis of UN voting, see Russett (1966). A Q-factor analysis of nations on many of their characteristics has been reported by Banks and Gregg (1965).
5. Most factor analysis done on nations has been R-factor analysis. As one example out of many, see Tanter (1966). R- and Q-factor analyses do not exhaust the kinds of patterns that may be considered. Other possible patterns of variation are those in characteristics over time units for a specified nation (this identifies similar time periods); in nations over time units for a characteristic (this identifies nations similarly changing on a characteristic); and in time units over nations for a characteristic ( this identifies similar time periods for nations changing on a characteristic). For a discussion of these varieties of analysis, see Rummel (1970, Chapter. 8).
6. Section 4.2 discusses how such percentage figures are derived from the factor results.
7. For example, see Borgatta and Cottrell's classificatory work on groups (1955) and Schuessler and Driver's on tribes (1956). Selvin and Hagstrom (1963) show, through an example, how to use factor analysis to develop a classification of groups. Using factor analysis, Russett classifies nations into their regional groups (1967) and their UN voting blocs (1966).
8. For practical applications of this two-step design, see Buckatzsch ( 1947) and Berry (1960).
9. On this and related points, see the particularly excellent Chapters 19 and 20 in Cattell (1952). Cattell (1966) has recently elaborated the position that factor analysis is, among other things, an experimental method.
10. See the discussion on the relationship between hypotheses and factor analysis in Cattell (1952, pp. 13-14). For an application of factor analysis to test a hypothesis about the supposed dimensions of urban areas, see van Arsdol, Camilleri, and Schmid (1958).
11. An extended discussion of description and explanation with regard to factor analysis in psychology is given by Henrysson (1957). Thurstone (1947, Chapter 6) discusses factors as explanatory concepts in terms of a demonstration problem involving the dimensions of cylinders. His illustration of this problem is helpful for understanding factor analysis in practice.
12. The distinction being drawn here is between descriptive and inferential statistics, not between description and statistics.
13. Some of the more excellent treatments are those by Frank (1955, Chapter 1), Kaufmann (1958, Chapter 6), the essays by Russell, Feigl, and Nagel in Part V of Feigl and Brodbeck (1953), and Nagel (1961).
14. "It would seem that in general the variables highly loaded in a factor are likely to be the causes of those which are less loaded, or at least that the most highly loaded measures--the factor itself--is causal to the variables that loaded on it" (Cattell, 1952, p. 362). Cattell and Sullivan (1962) conducted a demonstration experiment by factoring data on cups of coffee to determine whether patterns corresponding to known causal influences could be delineated. They found a strong correlation between the known patterns of influences and those defined by the factor analysis. With like results a similar experiment was conducted on the dynamics of balls (Cattell and Dickman, 1962). These artificial experiments are helpful in understanding applied factor analysis.
15. Positive empirical evidence for this view is referred to in Note 14.
16. See the clear and explicit analysis by Abel (1953) of the operation of verstehen in the social sciences.
17. One of the best discussions of theory is given by Nagel (1961, Chapter 6). That theory construction consists of two parts is argued by Einstein. See the essays on Einstein's philosophy by Frank, Lenzen, and Nortbrup in Schilpp (1949).
18. An exciting theoretical use of factor analysis has been published by Cattell. (1962). He describes a role behavior model potentially rooted in empirical data, tying together personality, structure, and syntal group dimensions. A theoretical embodiment of factor analysis to relate the attributes and behavior of social units is described in Rummel (1965).
19. The relationship between classical physics and quantum theory, or between Cartesian analysis and Hilbertian analysis as related to factor analysis, is discussed by Ahmavaara (Ahmavaara and Markkanen, 1958, pp. 48-63). This analysis is the most refreshing and provocative that I have read on the subject. See also Note 25, below.
20. Prior to plotting, the data would have to be made comparable through some standardization procedure.
21. The cosine of this angle between vectors is, with minor qualifications, equal to the product moment correlation coefficient between the characteristics represented by the vectors. Thus, a correlation of 1.00 between two variables on twenty cases means that the angle is zero between the two vectors (variables) plotted in the space of twenty dimensions (cases).
22. I am referring to the results of the factor analysis research design, which include the application of a factoring technique plus simple structure rotation. (See Section 5.2) For those familiar with linear algebra, it may be helpful to know that a factor analysis defines a set of basis dimensions for the column vectors of a data matrix. Each basis dimension of a rotated set uniquely generates an independent subset of the original vectors. The basis dimensions of an unrotated set are ordered by their contributions to generating all the vectors.
23. The configuration of vectors in Figure 5 is four-dimensional. Therefore, although the placement of the two independent axes is the best (orthogonal) definition of the two clusters in four-dimensional space, the two-dimensional figure can only display this fit imperfectly.
24. This is where curve-fitting techniques like multiple linear and curvilinear regression analysis are helpful.
25. The factor analysis model has much in common with quantum theory. This is one reason I have argued, as I do in Section 2.5 above, that factor analysis is a theoretical structure as well as a data analysis technique. See Margenau (1950, Chapter 17) for a clear and simple description of quantum theory. Burt (1941) and Ahmavaara in Ahmavaara and Markkanen (1958) have also drawn the comparison of factor analysis with quantum theory.
26. Confusion on this score has caused much unfounded criticism of factor analysis as delineating only linear relationships.
27. The idea of a correlation coefficient gives another perspective on factor analysis. The patterns discovered by a factor analysis consist of those variables highly intercorrelated. Thus, if variable A is highly correlated with both B and C, and if B and C are highly correlated with each other, then A, B, and C form a correlation cluster. If A, B, and C are not correlated with other variables, then they form an independent pattern that factor analysis will delineate.
28. There is some question about the criteria for determining the exact number of factor patterns for a set of data. Variation in the number of patterns defined by different criteria is usually small and, at any rate, normally concerns the minor patterns. The larger patterns, involving many variables with high loadings, will ordinarily be found and reported regardless of the criteria employed.
29. Note how the organization of a factor matrix is like the layout of Equation 1. Rather than explicitly organizing the factor results in equations, factor analysts use the matrix format, where the first column refers to the F1
, that have been found by the analysis.
30. These patterns differ from those given as examples for these variables in Section 1. This is because we are now discussing unrotated patterns. The reason for the differences will be discussed below.
31. To say the factors are uncorrelated means that the factor scores (to be discussed in Section 4.5) on the factor patterns are uncorrelated, and not necessarily the factor loadings. Factor loadings are, however, independent (orthogonal)
32. The eigenvalues are extracted only if the principal axes method of factor analysis is used. An eigenvalue is the root of the characteristic equation [R - 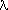 I] = 0, where R is the correlation matrix, is an eigenvalue, I is an identity matrix, and the brackets mean that the determinant is being computed. Let X be an orthogonal matrix with columns determined such that XR = X. Then the various roots, , are the eigenvalue solutions to the equation and X is the matrix of eigenvectors. The factor matrix is equal to the eigenvectors times the reciprocal square root of their associated eigenvalues.
I] = 0, where R is the correlation matrix, is an eigenvalue, I is an identity matrix, and the brackets mean that the determinant is being computed. Let X be an orthogonal matrix with columns determined such that XR = X. Then the various roots, , are the eigenvalue solutions to the equation and X is the matrix of eigenvectors. The factor matrix is equal to the eigenvectors times the reciprocal square root of their associated eigenvalues.
33. Although equal to the sum of squared factor loadings, the eigenvalue is technically a solution of the characteristic equation (see Note 32) for the unrotated factors. The rotated factors are derived from these by transformation (rotation).
34. The pattern matrix loadings are best understood as regression coefficients of the variables on the patterns.
35. These factor scores then give values for each case on the functions, F, of Equations 1, 2, and 3 in Section 3.2. With the constant, , defined by the factor matrix, and the factor scores defining the value of the function, F, the factor equations are completely specified.
36. At this point the reader may find it helpful to review Section 3.1.
37. Various mathematical criteria are employed to achieve oblique simple structure, and have such exotic names as quartimin, covarimin, biquartimin, binormin, promax, and maxplane. These may sometimes appear in the title of an oblique factor matrix.
Ahmavaara, Yrjö, and Tourco Markkanen. The Unified Factor Model. The Finnish Foundation for Alcohol Studies, 1958.
Alker, Hayward, Jr. "Dimensions of Conflict in the General Assembly." American Political Science Review, 58 (1964), 642-57.
________ and Bruce Russett. World Politics in the General Assembly. New Haven, Conn.: Yale University Press, 1965.
Banks, Arthur S., and Phillip M. Gregg. "Grouping Political Systems: Q-Factor Analysis of 'A Cross-Polity Survey,'" American Behavioral Scientist, 9 (1965), 3-6.
BERRY, Brian J. L. "An Inductive Approach to the Regionalization of Economic Development." In Norton Ginsburg (ed.), Essays on Geography and Economic Development. Chicago: University of Chicago Press, 1960.
Borgatta, E. F., and L. S. Cottrell, Jr. "On the Classification of Groups," Sociometry, 18 (1955), 665-678.
Buckatzsch, E. J. "The Influence of Social Conditions on Mortality Rates," Population Studies, 1 (1947), 229-48.
Burt, C. The Factors of the Mind. New York: Macmillan, 1941.
Cattell, Raymond B. Factor Analysis. New York: Harper Brothers, 1952.
________. "Group Theory, Personality and Role: A Model for Experimental Researches." In F. A. Geldard (ed.), NATO Symposium an Defense Psychology. New York: Pergamon Press, 1962.
________. "Multivariate Behavioral Research and the Integrative Challenge," Multivariate Behavioral Research, 1 (Jan. 1966), 4-23.
________. "The Dimensions of Culture Patterns by Factorization of National Characters," Journal of Abnormal and Social Psychology, 44 (1949), 443-469.
________, and K. Dickman. "A Dynamic Model of Physical Influences Demonstrating the Necessity of Oblique Simple Structure," Psychological Bulletin, 59 (1962), 3894M.
________, and William Sullivan. "The Scientific Nature of Factors: A Demonstration by Cups of Coffee," Behavioral Science, 7 (1962), 184-93.
Ezekiel, Mordecai, and Karl A. Fox. Methods of Correlation and Regression Analysis, 3rd Edition. New York: Wiley and Sons, 1959.
Feigl, Herbert, and May Brodbeck (eds.). Readings in the Philosophy of Science. New York: Appleton Century Crofts, 1953.
Frank, Philip. Modern Science and its Philosophy. New York: Braziller, 1955.
Hanson, Norwood Russell. "On the Symmetry Between Explanation and Prediction," The Philosophical Review, 68 (1959), 349-58.
Hempel, Carl G. Aspects of Scientific Explanation and Other Essays in the Philosophy of Science. New York: Free Press, 1965.
________. "Fundamentals of Concept Formation in Empirical Science." International Encyclopedia of Unified Science, 2. Chicago: University of Chicago Press, 1952.
Henrysson, Sten. Applicability of Factor Analysis in the Behavioral Sciences. Stockholm: Almqvist and Wiksell, 1957.
Kaufmann, Felix. Methodology of the Social Sciences. New York: Humanities Press, 1958.
Margenau, Henry. The Nature of Physical Reality. New York: McGraw-Hill, 1950.
Nagel, Ernest. The Structure of Science. New York: Harcourt, Brace and World, 1961.
Rummel, R. J. "A Field Theory of Social Action with Application to Conflict Within Nations." General Systems Yearbook, 10 (1965), 183-211.
________. Applied Factor Analysis. Evanston, ILL: Northwestern University Press.
________. "Some Attribute and Behavioral Patterns of Nations," Journal of Peace Research, 2 (1967), 196-206.
________. The Dimensions of Nations. Beverly Hills, CA: Sage Publications, 1972.
Russett, Bruce. "Delineating International Regions." In J. David Singer (ed.), Quantitative International Politics. Glencoe: Free Press, 1967.
________. "Discovering Voting Groups in the United Nations," American Political Science Review, 60 (June 1966), 327-39.
Schilpp, Paul Arthur (ed.). Albert Einstein: Philosopher-Scientist. Evanston: Library of Living Philosophers, 1949.
Schuessler, K. F., And Harold Driver. "A Factor Analysis of Sixteen Primitive Societies," American Sociological Review, 21 (1956), 493-9.
Selvin, Hanan C., And Warren 0. Hagstrom. "The Empirical Classification of Formal Groups," American Sociological Review, 28 (1963), 399-411.
Tanter, Raymond. "Dimensions of Conflict Behavior Within and Between Nations, 1958-60," Journal of Conflict Resolution, 10 (March 1966), 41-64.
Thurtstone, L. L. Multiple-Factor Analysis. Chicago: University of Chicago Press, 1947.
Van Arsdol, Maurice D., Jr., Santo F. Camilleri, and Calvin F. Schmid. "The Generality of Urban Social Area Indexes," American Sociological Review, 23 (1958), 277-84.
Alker, Hayward, Jr. "Dimensions of Conflict in the General Assembly," American Political Science Review, 58 (1964), 642-57.
________. "Supranationalism in the United Nations," Peace Research Society: Papers III, 1965, Peace Research Society (International) Chicago Conference, 1964.
________, and Bruce M. Russett. World Politics in the General Assembly. New Haven, Conn.: Yale University Press, 1965.
Banks, Arthur S., and Phillip Gregg. "Grouping Political Systems: Q-Factor Analysis of 'A Cross-Polity Survey,' " American Behavioral Scientist, 9 ( 1965), 3-6.
Berry, Brian J. L. "An Inductive Approach to the Regionalization of Economic Development." In Norton Ginsburg (ed.), Essays on Geography and Economic Development. Chicago: University of Chicago Press, 1960.
________. "Basic Patterns of Economic Development." In Norton Ginsburg (ed.), Atlas of Economic Development. Chicago: University of Chicago Press, 1961, 110-19.
Cattell, Raymond B. "A Quantitative Analysis of the Changes in Culture Pattern of Great Britain, 1837-1937, by P-Technique," Acta Psychologica, 9 (1953), 99-121.
________. "The Dimensions of Culture Patterns by Factorization of National Characters," Journal of Abnormal and Social Psychology, 44 (1949), 443-69.
________. "The Principal Culture Patterns Discoverable in the Syntal Dimensions of Existing Nations," Journal of Social Psychology, 32 (1950), 215-53.
________. and Marvin Adelson. "The Dimensions of Social Change in the U.S.A. as Determined by P-Technique," Social Forces, 30 (1951), 190-201.
________, H. Breul, and H. P. Hartman. "An Attempt at More Refined Definitions of the Cultural Dimensions of Syntality in Modern Nations," American Sociological Review, 17 (1952), 408-21.
________, and Richard L. Gorsuch. "The Definition and Measurement of National Morale and Morality," Journal of Social Psychology, 67 (1965), 77-96.
Chadwick, Richard W. Developments in a Partial Theory of International Behavior: A Test and Extension of Inter-Nation Simulation Theory, Ph.D. dissertation, Northwestern University, 1966.
Denton, Frank H. "Some Regularities in International Conflict, 1820-1949," Background, 9 (Feb. 1966), 283-96.
Feierabend, Ivo K., and Rosalind L. "Aggressive Behaviors Within Polities, 1948-1962: A Cross-National Study," Journal of Conflict Resolution, 10, 3 (Sept. 1966), 249-71.
Gibb, Cecil A. "Changes in the Culture Pattern of Australia, 1906-1946, as Determined by the P-Technique," Journal of Social Psychology, 43 (1956), 225-38.
Gregg, Phillip M., and Arthur S. Banks. "Dimensions of Political Systems: Factor Analysis of 'A Cross-Polity Survey,'" American Political Science Review, 59 (Sept. 1965), 602-14.
Hatt, Paul K., Nellie L. Farr, and Eugene Weinstein. "Types of Population Balance," American Sociological Review, 20, 1 (Feb. 1955), 14-21.
Laulicht, Jerome. "An Analysis of Canadian Foreign Policy Attitudes," Peace Research Society: Papers III, 1965, Peace Research Society (International) Chicago Conference, 1964.
McClelland, C., et al. The Communist Chinese Performance in Crisis and Non-Crisis: Quantitative Studies of the Taiwan Straits Confrontation, 1950-64. Final Report of Completed Research under contract for Behavioral Sciences Group, Naval Ordnance Test Station, China Lake, Calif. (N60530-11207), Dec. 14, 1965.
Megee, Mary. "Problems in Regionalization and Measurement," Peace Research Society: Papers IV, 1966, Peace Research Society (International), Cracow Conference (1965), 7-35.
Morris, Charles. Varietics of Human Value. Chicago: University of Chicago Press, 1956.
Rummel, R. J. "A Field Theory of Social Action with Application to Conflict Within Nations," General Systems Yearbook, 10 1965), 183-211.
________. "A Social Field Theory of Foreign Conflict," Peace Research Society: Papers IV, 1966, Peace Research Society (International), Cracow Conference, 1965a.
________. "Dimensions of Conflict Behavior Within and Between Nations," General Systems Yearbook, 8 (1963), 1-50.
________. "Dimensions of Conflict Behavior within Nations, 1946-1959," Journal of Conflict Resolution, 10, 1 (March 1966), 65-73.
________. "Dimensions of Dyadic War, 1820-1952," Journal of Conflict Resolution, 11, 2 (June 1967), 176-83.
________. "Dimensions of Foreign and Domestic Conflict Behavior: Review of Findings." In Dean Pruitt and Richard Snyder (eds.), Theory and Research on the Causes of War. Englewood Cliffs, N.J.: Prentice-Hall, 1969.
________. "Some Attribute and Behavioral Patterns of Nations," Journal of Peace Research, 2 (1967), 196-206.
________. "Some Dimensions in the Foreign Behavior of Nations," Journal of Peace Research, 3 (1966), 201-24.
________. Dimensions of Nations. Santa Barbara, CA: Sage Publications, 1972.
Russett, Bruce M. "Delineating International Regions." In J. David Singer (ed.), Quantitative International Polities. Glencoe: Free Press, 1968.
________. "Discovering Voting Groups in the United Nations," American Political Science Review, 60 (June 1966), 327-39.
________ International Regions and International Integration. Chicago: Rand McNally, 1967.
Schnore, Leo F. "The Statistical Measurement of Urbanization and Economic Development," Land Economics, 37, 3 (Aug. 1961), 229-45.
Tanter, Raymond. "Dimensions of Conflict Behavior \\1ithin Nations, 1955-1960: Turmoil and Internal War," Peace Research Society: Papers III, 1965, Peace Research Society (International) Chicago Conference, 1964.
________. "Dimensions of Conflict Behavior Within and Between Nations, 1958-60," Journal of Conflict Resolution, 10 (March 1966), 41-64.
 visitor since 11/27/02
visitor since 11/27/02Go to top of document
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}